Detecting malicious web pages using an ensemble weighted average model
-
Thesis Project - Malicious website classification
-
Data sets used in Literature with accuracy levels
-
Details of Original & Processed Data Sets
-
URL generated features
-
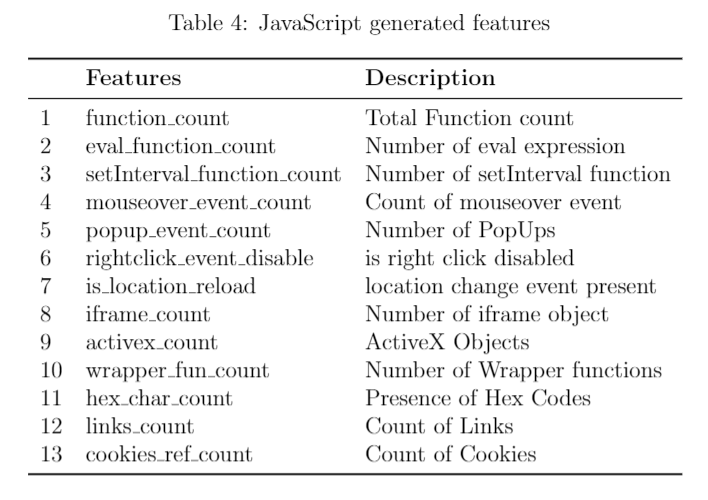
JavaScript generated features
-
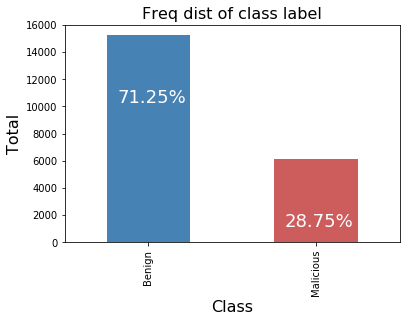
Class Imbalance of Final Dataset
-
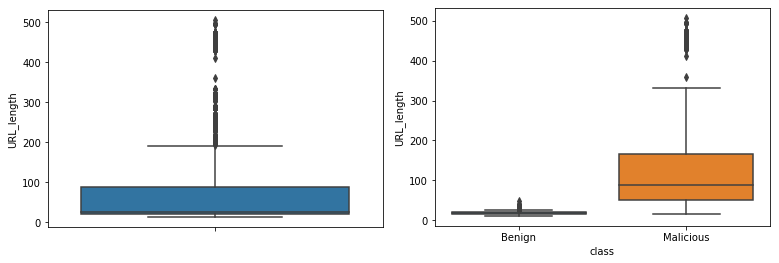
Box Plot - URL length vs Class label
-
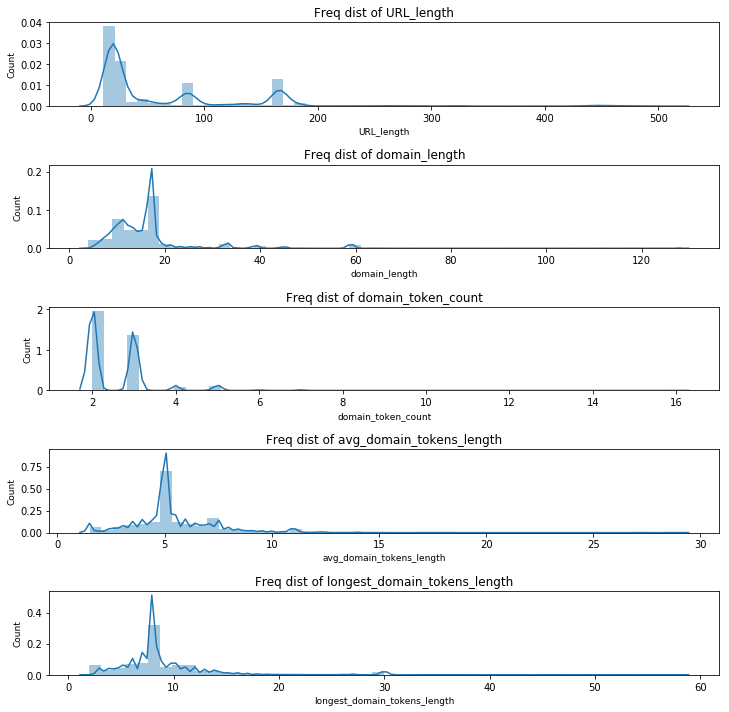
Histogram of Numeric features
-
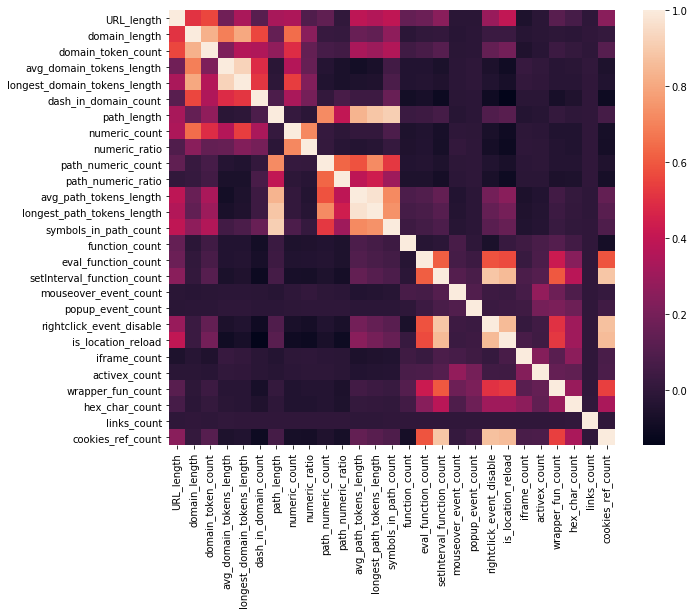
Correlation Matrix
-
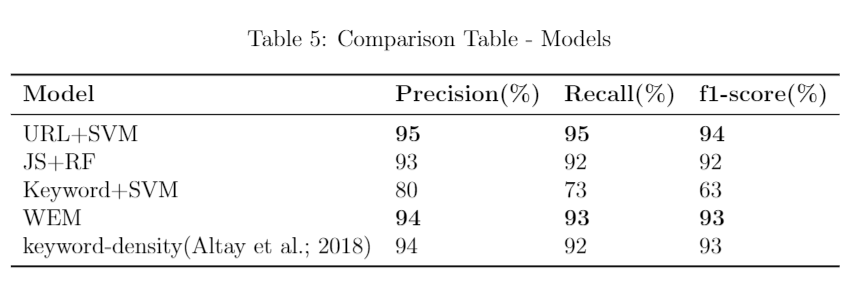
Comparison Table - Models
-
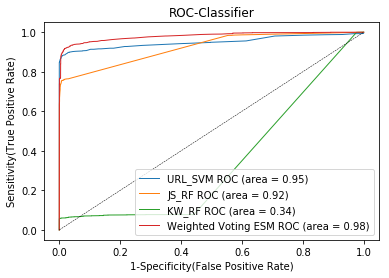
Algorithms Accuracy Comparison
Project Description
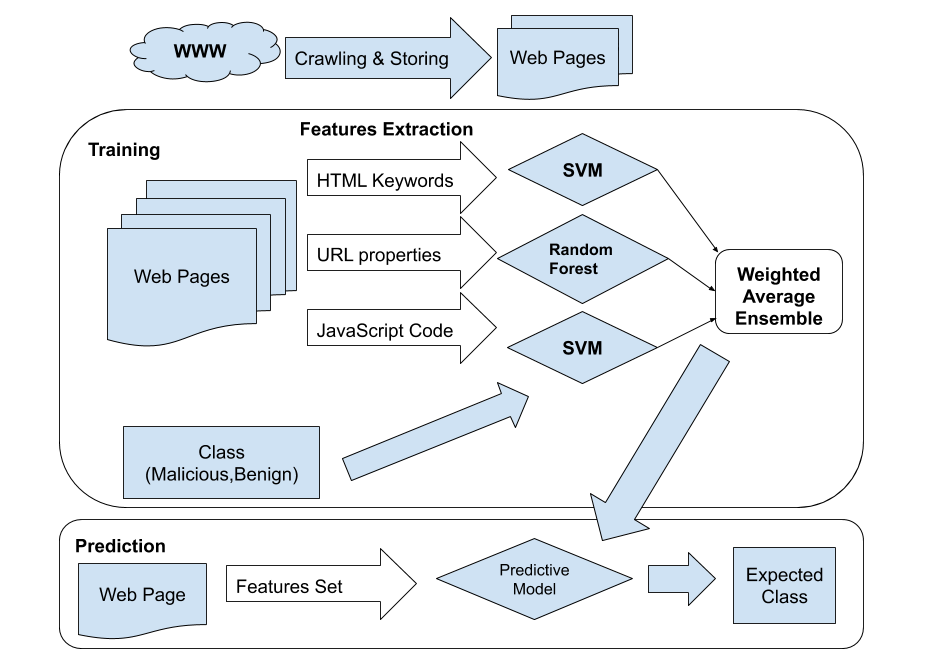
Websites are the most common platform which gets exploited for user-sensitive information in the case of cyber crime activites. The present solutions include black-listing URLs, awareness programs and ethical policies to prevent from malicious websites. However, due to the increasingly changing web, static techniques like black-list fails to cover recently infected web pages. Thus, this research focuses on developing an intelligent system based upon a machine learning model to detect such web pages. In this research, an effort is made to improve this classification problem using URL, JavaScript and HTML contents over keyword density-based model. These features are independently analysed and modelled using a combination of SVM and Random Forest. Further, a weighted average ensemble model is built using a subset of features with the individual model. The optimal weights of (2,3,2) are determined and given to URL, JavaScript and HTML models. The developed models are assessed with the help of performance metrics like precision, recall and f1-score and the best model shows that it can identify fraudulent web URLs with the precision of 95%, recall of 95% and f1-score of 94%.
Project Details
Module Name: Research Project
Duration: May, 2019 - August, 2019
Research Presentation
Thesis Report Document
Report User Manual
Note:
These documentations are shared only as a demonstration of work of author and any contents copied or referred or recreated in any means for own academic or professional purposes will not be accepted and legal actions would be taken against those offenders.
View All ProjectsCopyright © Dharmendra Vishwakarma (vdharam), 2024 | This site is hosted on GitHub Pages and last updated on 28th December, 2025. | Check Website Code
Connect with me : LinkedIn | Twitter | Github | Codepen | StackOverflow | Free Code Camp | HackerRank | Quora | Medium | DataCamp